GPT-3 → GPT-4 → GPT-4o → GPT-5 → GPT-5.2 → GPT-5.3 → GPT-5.4 → GPT-5.5의 성능 진화, Claude Opus와 Gemini 최신 릴리즈 흐름, GLM-5.1 같은 오픈 모델의 추격, LLM 동작 원리, benchmark 해석, Local vs Cloud 전략, agentic coding tool explosion, 그리고 하드웨어 엔지니어의 역할 변화를 세미나용으로 재정리한 HTML 자료입니다.
업데이트 버전 · 2026-04-27 · GitHub Trending 보강그래픽 타임라인 + 수치 비교 포함
현재 표시 버전임베디드 기본본
게시일2026-04-27
상태
게시판과 버전 정보를 불러오는 중입니다.
이 페이지는 매일 오전 9시에 최신 뉴스와 사용자 의견을 반영하여 자동으로 업데이트됩니다.
01 REASONING TRAJECTORY
GPT-3에서 GPT-5.5까지: “텍스트 생성기”에서 “실행 가능한 에이전트”로
2020년에는 few-shot generalization, 2021년에는 자연어→코드 인터페이스, 2022년에는 instruction following과 대화형 인터페이스, 2023년에는 고난도 추론, 2024년에는 실시간 멀티모달, 2025년에는 라우터와 사고 깊이, 2026년에는 computer-use·터미널 코딩·전문 업무 산출물까지 결합된 실행형 에이전트로 진화했습니다.
불과 6년 만에, LLM은 이렇게 바뀌었습니다
텍스트 생성기에서 대화형 모델로, 다시 멀티모달·에이전트형 모델로 넘어온 흐름을 시간순으로 정리했습니다.
주요 모델과 전환점
2020년 GPT-3부터 2026년 프론티어 모델까지의 변화입니다.
2021.06 · GitHub/OpenAI
Copilot / Codex
자연어로 코드를 설명하면 바로 함수와 코드 조각을 제안하는 UX를 대중화하며, 이후 에이전트 코딩 흐름의 출발점 가운데 하나가 됐습니다.
2022.01 · OpenAI
InstructGPT
RLHF와 instruction following을 전면화하며 “다음 토큰을 잘 맞히는 모델”을 “사람 지시를 더 잘 따르는 모델”로 바꾸는 전환점을 만들었습니다.
2023.08 · NAVER
HyperCLOVA X
한국어 중심 초거대 모델을 상용 라인업으로 올리며, 한국어 reasoning·문화 맥락 이해·소버린 AI 축의 대표 사례가 됐습니다.
2024.03 · Anthropic
Claude 3 Opus
GPQA 같은 graduate-level expert reasoning benchmark에서 강세를 보이며, “복잡한 지식 작업” 시장에서 Claude의 존재감을 키운 전환점이었습니다.
2025.01 · DeepSeek
DeepSeek-R1
대규모 RL 기반 reasoning 모델을 공개 가중치로 풀며, “오픈 모델도 frontier 추론에 근접할 수 있다”는 인식을 시장에 강하게 남겼습니다.
2025.03 · Google
Gemini 2.5 Pro
thinking model을 전면에 내세우며 AIME 2025·GPQA·HLE 같은 reasoning benchmark에서 선두권을 기록했습니다.
GDPval 70.9%, SWE-bench Verified 80.0으로 전문 지식 업무와 long-running agent 성능이 본격화됐습니다.
GPT-5.3-Codex · 2026.02.05
agentic coding 전용선의 도약
SWE-Bench Pro 56.8%, Terminal-Bench 2.0 77.3%를 공개하며 Codex가 코드 작성기를 넘어 컴퓨터 업무 agent로 확장되는 흐름을 만들었습니다.
GPT-5.4 · 2026.03.05
computer-use와 실제 작업 완료 능력
GDPval 83.0, OSWorld-Verified 75.0, 1M context, computer use 성능 향상으로 “일을 끝내는 모델”에 더 가까워졌습니다.
GPT-5.5 · 2026.04.23
agentic coding과 지식 업무 실행력의 재도약
Terminal-Bench 2.0 82.7, SWE-Bench Pro 58.6, GDPval 84.9, OSWorld-Verified 78.7로 GPT-5.4 대비 실제 작업 수행 지표가 다시 상승했습니다.
OpenAI 공개 지표 기준: 주요 모델 비교 그래프
OpenAI 공개 수치 흐름을 GPT-5.5까지 확장하고, 여기에 Qwen·Gemini·Claude·Grok·HyperCLOVA의 공식 공개 benchmark를 추가했습니다. 글로벌 frontier benchmark와 한국어 특화 benchmark를 나눠서, 어떤 축에서 누가 강한지 한눈에 보이도록 재구성했습니다.
벤치마크 이름이 어려워 보여도 실제 질문은 단순합니다. GDPval은 직장 업무 산출물을 얼마나 사람답게 만드는가, OSWorld-Verified는 컴퓨터를 실제로 조작할 수 있는가, SWE-bench 계열은 실제 저장소의 이슈를 고칠 수 있는가를 묻는 시험입니다.
GDPval = 직장 업무 산출물 시험
OpenAI의 GDPval은 44개 직종에서 실제로 쓰이는 산출물—예를 들어 legal brief, engineering blueprint, customer support conversation, nursing care plan, slide, spreadsheet, diagram, short video—을 만들게 하고 전문가와 비교합니다.
점수 의미: 모델 출력이 전문가와 동급 이상으로 판정된 비율입니다. 즉 84.9는 “비교의 약 85%에서 professional-quality”에 가깝다는 뜻입니다.
0–30초안 보조 수준
30–60일부 업무에서 실무 보조
60–80여러 직무에서 professional-grade
80+대다수 비교에서 전문가급
예: GPT-5.5의 84.9는 “잘 정의된 knowledge work 다수에서 전문가와 동급/이상”으로 읽는 것이 가장 직관적입니다.
OSWorld-Verified = 컴퓨터를 실제로 다루는 시험
OSWorld는 우분투/데스크톱 환경에서 파일 관리, 앱 제어, 문서 작업, 웹 작업, 멀티앱 workflow를 실제로 수행하게 하는 benchmark입니다. 채점은 화면 보기만이 아니라 실행 결과로 성공/실패를 가립니다.
점수 의미: 성공한 실제 컴퓨터 태스크의 비율입니다. 공식 OSWorld 기준 human performance는 72.36%, OpenAI 공개 기준 GPT-5.5는 78.7%입니다.
0–30간단한 GUI 조작 일부
30–50단순 task 수행 가능
50–70강한 digital operator
70+이 benchmark에서 인간 숙련 사용자권
즉 OSWorld 70+는 “말을 잘하는 모델”이 아니라 “실제 컴퓨터를 다루는 사용자”에 가까워졌다는 신호입니다.
SWE-bench = 실제 GitHub 이슈 해결 시험
SWE-bench Verified는 12개 Python 오픈소스 저장소의 실제 GitHub issue를 가져와, 모델이 코드를 고친 뒤 숨겨진 FAIL_TO_PASS 테스트를 통과하고 기존 PASS_TO_PASS 테스트를 깨뜨리지 않는지로 채점합니다.
점수 의미: 실제 저장소 이슈를 끝까지 해결한 비율입니다. Verified 주석 기준으로 easy는 15분 미만, hard는 1시간 초과로 추정된 이슈입니다.
0–20쉬운 이슈 일부 해결
20–40버그 수정 보조자
40–60실전 repo 문제 해결 보조
60+frontier coding agent tier
SWE-bench 계열은 단일 human 점수보다 “얼마나 많은 real issue를 독립적으로 해결했는가”로 읽는 편이 정확합니다.
4월 마지막 주의 흐름은 두 축입니다. OpenAI는 GPT-5.5로 에이전트 코딩과 컴퓨터 사용 성능을 다시 끌어올렸고, Z.AI의 GLM-5.1은 오픈 모델이 실전 코딩 benchmark에서 frontier proprietary model에 근접하거나 일부 지표에서 앞설 수 있음을 보여줬습니다.
GPT-5.5: 챗봇보다 에이전트 업무에 초점
OpenAI는 2026년 4월 23일 GPT-5.5를 ChatGPT와 Codex 유료 사용자에게 배포했습니다. 공식 수치 기준 Terminal-Bench 2.0은 82.7%, SWE-Bench Pro는 58.6%, GDPval은 84.9%, OSWorld-Verified는 78.7%입니다.
해석: 단순 지식 Q&A보다 터미널, 코드베이스, 도구, 운영체제 조작처럼 “실제로 일을 끝내는” 평가에서 개선 폭이 큽니다.
GLM-5.1: 오픈 모델의 코딩 추격
Z.AI 문서에는 GLM-5.1이 2026년 4월 7일 릴리스로 표기되어 있으며, 장시간 작업에서 최대 8시간 독립 실행을 지향한다고 설명됩니다. 관련 리뷰들은 3월 27일 초기 공개/접근 이후 4월 SWE-Bench Pro 58.4를 핵심 성과로 정리합니다.
해석: 첨부 벤치마크 기준으로 GLM-5.1은 SWE-Bench Pro에서 GPT-5.4 57.7, Claude Opus 4.6 57.3, Gemini 3.1 Pro 54.2를 근소하게 앞섭니다.
모델/주제
핵심 수치
세미나에서의 해석
GPT-5.5
Terminal-Bench 82.7, SWE-Bench Pro 58.6, GDPval 84.9, OSWorld 78.7
고급 코딩, 터미널 작업, 컴퓨터 사용, 전문 업무 산출물에서 GPT-5.4 대비 일관된 상승. 에이전트형 업무가 주전장이 됐다는 신호.
GLM-5.1
SWE-Bench Pro 58.4, CyberGym 68.7, NL2Repo 42.7, Terminal-Bench 63.5
코딩·보안·장시간 agentic task에서 오픈 모델 경쟁력이 크게 상승. 다만 HLE no-tools 31.0, GPQA 86.2처럼 순수 추론·과학 지식은 GPT/Gemini/Claude 상위권에 뒤지는 영역이 남음.
오픈 모델 전략
744B/754B급 MoE, 약 40B active, 200K context 계열
오픈 모델도 “작고 가벼운 로컬 모델”만이 아니라, 자체 인프라나 고메모리 장비를 요구하는 초대형 self-hosting 선택지로 분화.
하드웨어 관점
장시간 에이전트, 대형 컨텍스트, 도구 호출 증가
성능 경쟁은 모델뿐 아니라 메모리 대역폭, KV cache, 스토리지, 로그/검증 파이프라인, agent harness 운영 능력의 경쟁으로 이어짐.
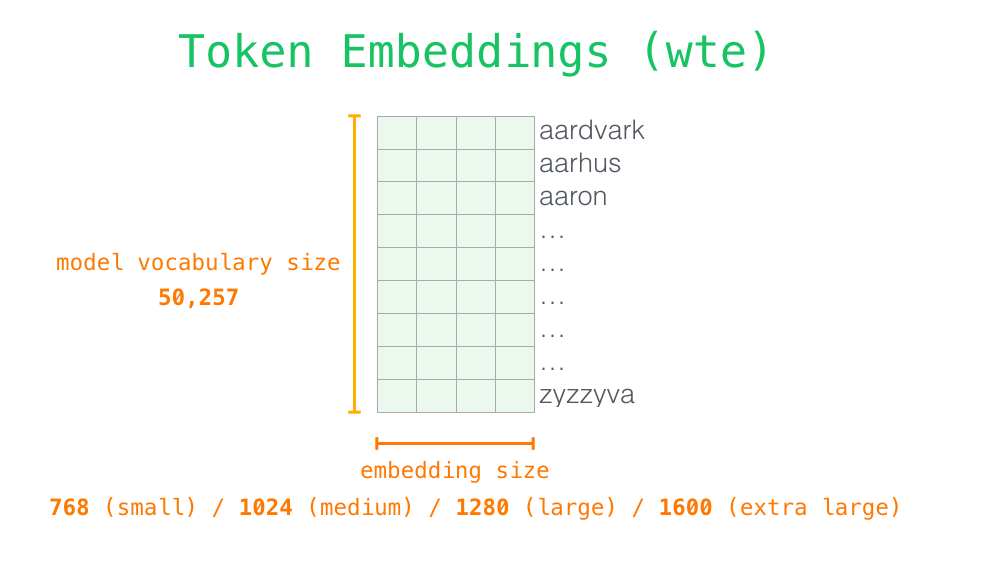
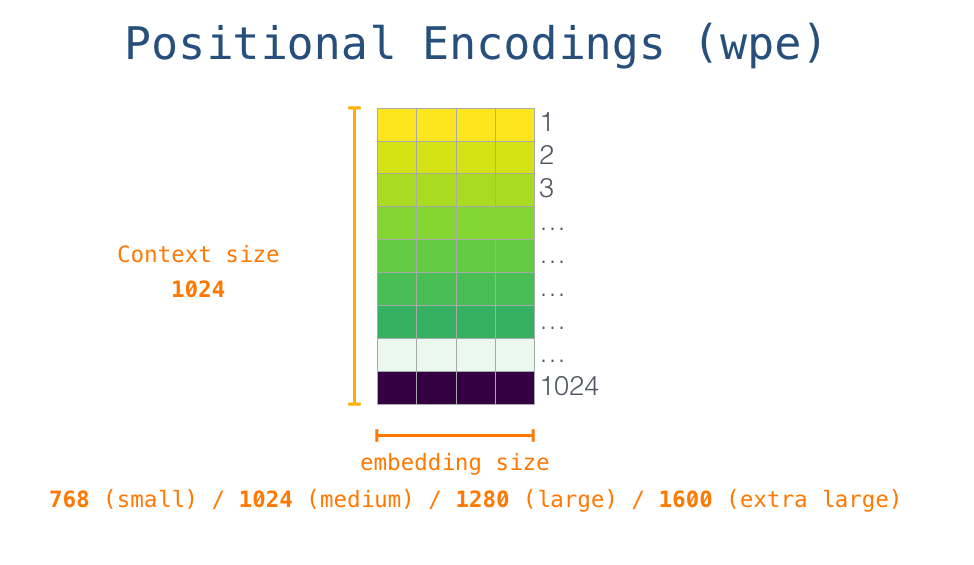
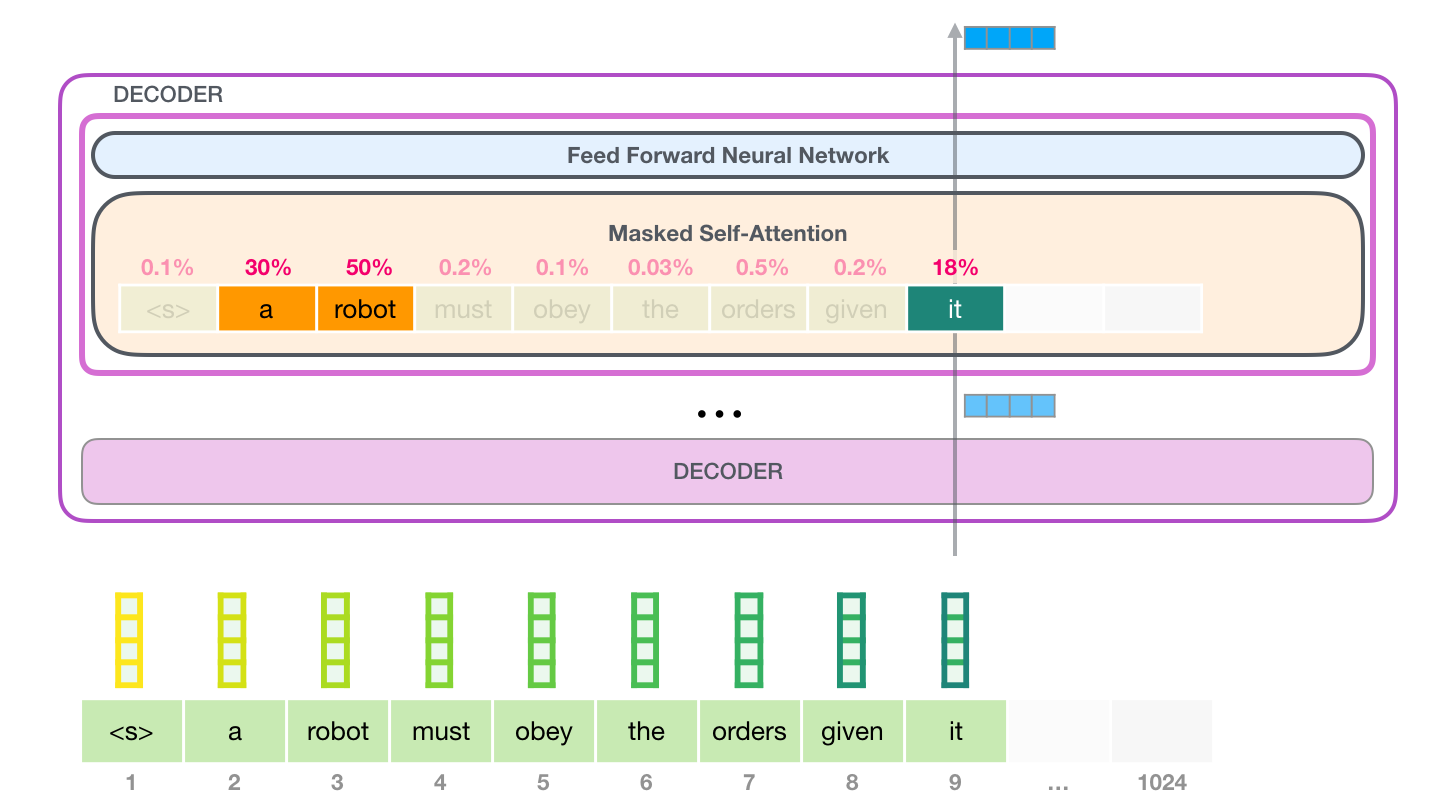
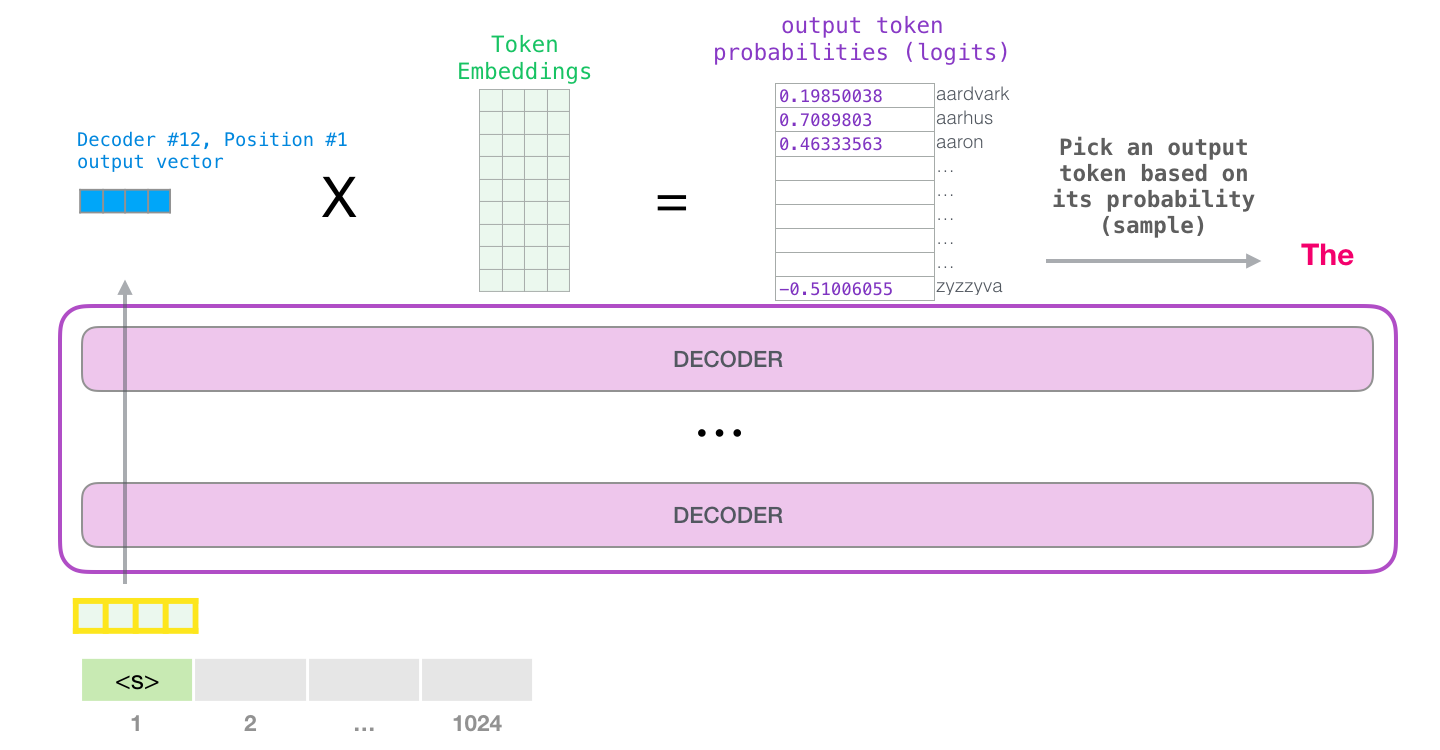
LLM은 텍스트를 토큰으로 바꾸고, 각 토큰을 벡터로 표현한 뒤, Transformer가 문맥 관계를 계산해 다음 토큰의 확률을 만들고, 이 과정을 반복해 문장을 생성하는 모델입니다. 이 장에서는 학습보다도 입력 → 문맥 계산 → 다음 토큰 생성이라는 실제 동작 순서에 초점을 맞춥니다.
실무 기본값은 여전히 Hybrid입니다. 2024년에는 GPT-4o와 Gemini 1.5 같은 cloud frontier가 시장을 주도했고, 2025년에는 Apple Mac Studio(M4 Max / M3 Ultra)와 NVIDIA DGX Spark·DGX Station 발표로 로컬 AI 컴퓨팅 관심이 크게 늘었습니다. 다만 실제 제품 운영 관점에서는 여전히 cloud·hybrid가 기본값이었고, 2026년에는 메모리 절감 연구와 경량·오픈 모델 성숙으로 local training이 아니라 local inference / fine-tuning / agent execution 쪽의 기회가 더 커지고 있습니다.
2024 → 2025 → 2026: Local vs Cloud 트렌드 변화
2024 | Cloud LLM이 대세
GPT-4o는 실시간 멀티모달 cloud flagship으로 자리 잡았고, Gemini 1.5도 AI Studio·Vertex AI 같은 cloud 경로에서 긴 컨텍스트와 효율을 밀었습니다.
키워드: frontier quality · API ecosystem · 멀티모달 · 실시간성
2025 | 로컬 실험 관심이 급증
Apple은 2025년 3월 Mac Studio를 M4 Max와 M3 Ultra로 갱신했고, NVIDIA는 같은 해 3월 DGX Spark·DGX Station을 발표했습니다. DeepSeek-R1과 Qwen3 같은 공개 모델도 더해지며 “개인/소규모 팀의 로컬 AI 실험”이 빠르게 늘었습니다.
키워드: Mac Studio refresh · DGX personal AI computers · open model experiment
2025 | 실전은 다시 Hybrid/Cloud
하지만 full training과 최상위 추론은 여전히 메모리·운영 효율의 벽이 컸습니다. NVIDIA도 DGX Spark를 “로컬에서 프로토타이핑하고, 이후 DGX Cloud나 데이터센터로 이어지는 시스템”으로 설명했고, DGX Spark 실제 출하는 2025년 10월부터 시작됐습니다.
키워드: local prototype, production hybrid/cloud, shipment late-2025
2026 | 변화 포인트
Google의 TurboQuant·KVCIS 같은 메모리 절감 연구와 Qwen3·Qwen3-Coder·Qwen Code 같은 로컬/에이전트 스택 성숙은 로컬 추론 여건을 개선하고 있습니다. 다만 M5 Ultra는 아직 Apple 공식 발표가 없으므로, 2026 로컬 재부상 논리는 “확정 사실”보다 “합리적 기대”로 보는 편이 정확합니다.
키워드: memory-efficient inference · local agent stack · M5 Ultra is still unannounced
2024: cloud frontier 우세
2025: Mac Studio refresh + DGX 발표로 local 실험 급증
2025 late: DGX Spark 출하, production 기본값은 hybrid/cloud
2026: 압축 연구 + 오픈 모델 성숙 + Mac mini 고메모리 수요 급증
2026년 4월 관찰: Mac mini 품절은 로컬 LLM 수요의 실물 신호
ZNews/Vietnam.vn 계열 보도는 2026년 4월 19일 기준 고메모리 Mac mini와 Mac Studio 일부 구성이 Apple Store에서 품절 또는 장기 배송 지연 상태였다고 전했습니다. 핵심은 단순 신제품 전환 신호가 아니라, 로컬 AI 에이전트와 대형 LLM을 직접 돌리려는 수요가 소비자용 고메모리 장비까지 압박하기 시작했다는 점입니다.
로컬 에이전트 장비 수요
고메모리 Mac mini / Mac Studio는 화면 없는 컴퓨트 노드처럼 쓸 수 있어, OpenClaw 같은 로컬 에이전트와 대형 언어모델 실험용으로 주목받고 있습니다.
DRAM/NAND 공급 압박
AI 데이터센터 확장은 HBM뿐 아니라 DRAM과 NAND 수요도 끌어올립니다. 그 결과 고메모리 PC, 개발 보드, 엣지 장비의 가격과 납기가 흔들리는 신호가 늘고 있습니다.
하드웨어 전략 변화
로컬 LLM은 “클라우드 대체”라기보다 기밀 처리, 비용 제어, 장시간 agent 실행, 장애 시 fallback을 위한 내부 컴퓨트 계층으로 봐야 합니다.
코딩의 중심이 “함수를 잘 호출하는 사람”에서 “대화 흐름과 에이전트 협업 구조를 설계하는 사람”으로 이동하고 있습니다. 중요한 변화는 단순 프롬프트가 아니라, 계획·라우팅·도구 사용·반복 검증, 그리고 이 전체를 감싸는 harness 설계가 이미 제품 내부에서 실행되기 시작했다는 점입니다.
1) Scripted API Call
프롬프트 → 응답 → 파서 → 다음 호출. 사람이 루프를 직접 설계하던 단계.
2) Chat-style Copilot
follow-up, 수정 요청, 맥락 유지가 가능해지며 코딩이 자연어 협업으로 변한 단계.
3) Multimodal Pairing
화면, 이미지, 오디오, 로그를 함께 보며 개발자와 모델이 동시 협업하는 단계.
4) Planner + Router
이미 제품 안으로 들어온 단계입니다. 모델이 작업을 여러 하위 과제로 나누고, 어떤 에이전트에 무엇을 맡길지, 어떤 도구를 쓸지, 다음 액션과 질문을 무엇으로 둘지 스스로 정합니다. 사람은 세부 프롬프트 작성보다 목표·우선순위·승인 기준을 정하는 쪽으로 이동합니다.
이미 진행 중
5) Agentic Execution
이미 확산 중인 단계입니다. 에이전트가 코드 수정, 테스트 실행, 실패 분석, 재시도, 병렬 실행까지 맡고, 사람은 최종 품질·리스크·우선순위를 감독합니다. 경쟁 포인트도 이제 “답변 한 번”보다 “여러 에이전트를 얼마나 안정적으로 운영하느냐”로 옮겨가고 있습니다.
이미 확산 중
6) Harness Engineering
이 단계에서 핵심 역량은 모델 바깥의 state · tools · permissions · verification · observability · retry loop를 설계하는 것입니다. 즉 하네스 엔지니어링은 에이전트가 장시간 안정적으로 일하도록 만드는 시스템 설계·운영 방법론에 가깝고, 단순 파이프라인 작성보다 더 넓은 개념입니다.
곧 확산 예정
프롬프트보다 환경, 단일 호출보다 루프 설계가 중요해지는 구간
“We may see the first AI agents join the workforce.”
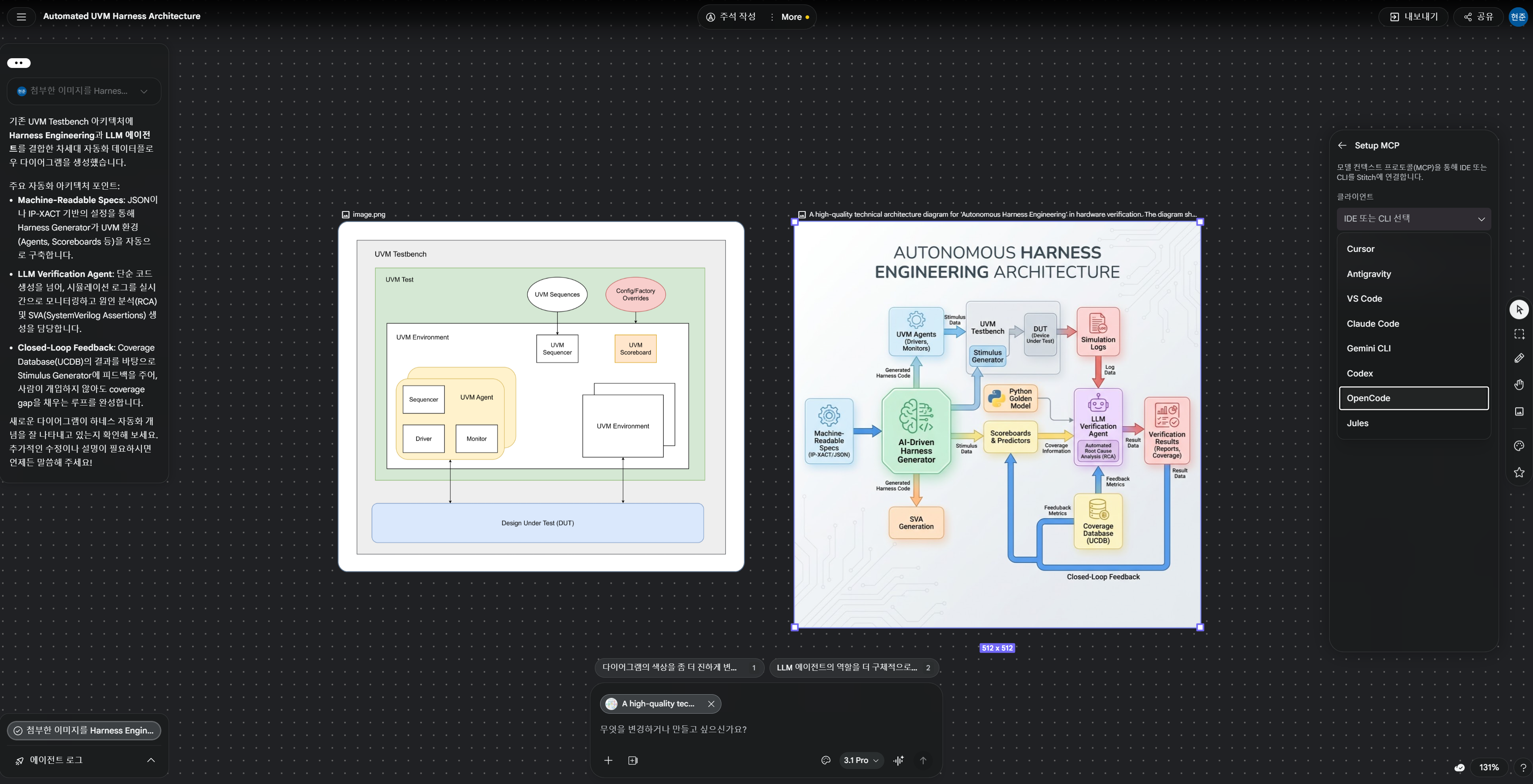
Hardware RTL에서 harness-engineered pipeline은 “LLM이 Verilog를 써준다”가 아닙니다. spec, microarchitecture, RTL, golden model, testbench, assertion, coverage, regression, sign-off evidence를 하나의 실행 가능한 검증 하네스로 묶어, 설계 변경이 생길 때마다 품질 신호가 자동으로 되돌아오게 만드는 방식입니다.
RTL harness loop: intent에서 sign-off evidence까지
Spec / Interface
레지스터 맵, 프로토콜, latency, reset, clock-domain, power intent를 명세화합니다.
Microarchitecture
pipeline, FSM, buffering, backpressure, arbitration 후보를 만들고 trade-off를 기록합니다.
RTL Candidate
SystemVerilog/VHDL 구현을 branch별 후보로 만들고 lint, CDC/RDC, synthesis rule을 즉시 적용합니다.
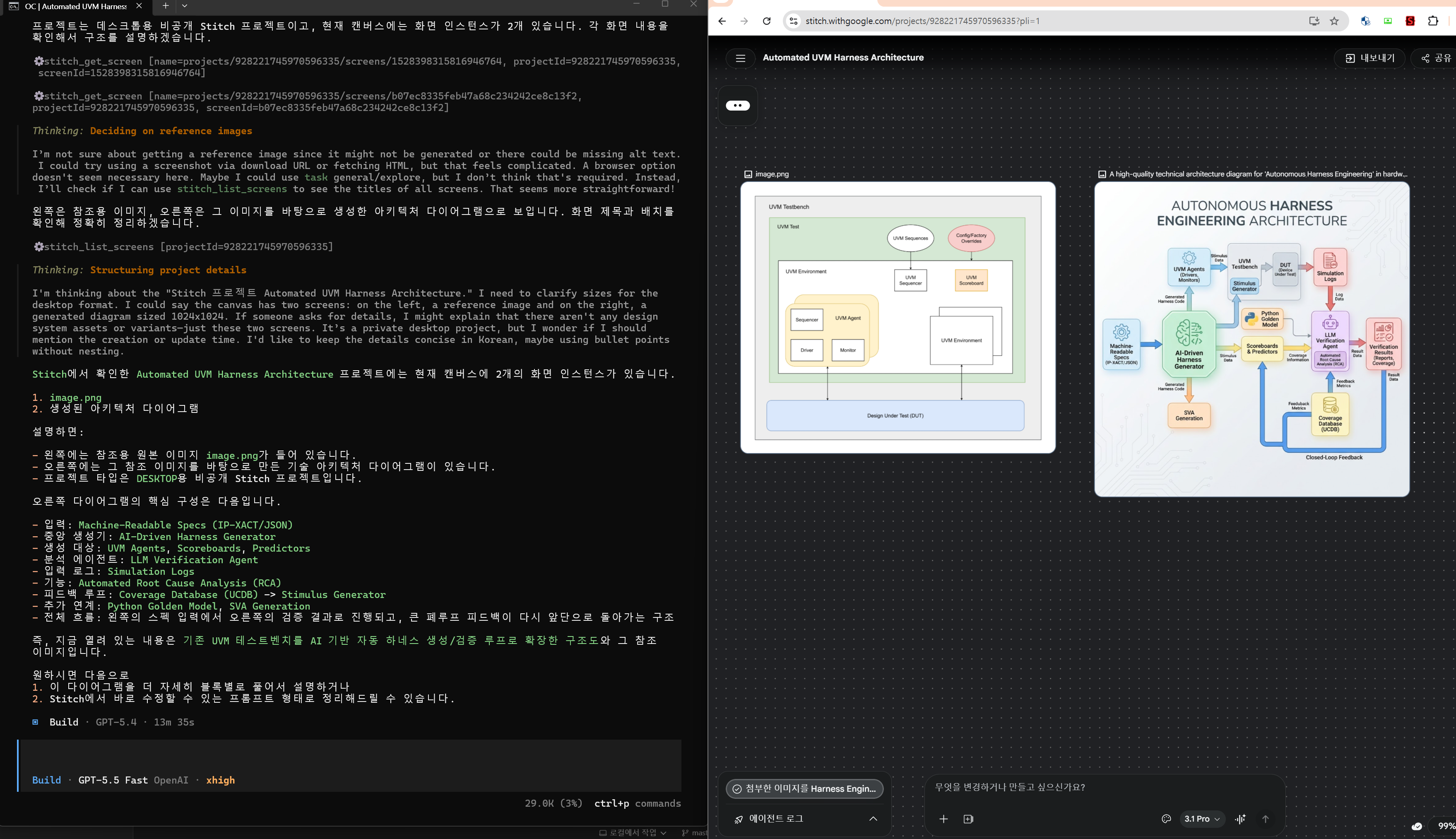
로컬 생성 이미지: Autonomous Harness Engineering Architecture
Stitch와 MCP를 통해 만든 최종 process_8.html 다이어그램으로 교체했습니다. RTL 설계, DV 하네스, 시뮬레이터, coverage/regression, sign-off evidence가 한 루프로 묶이고, 실패 로그가 다시 에이전트와 사용자 승인 게이트로 되돌아오는 구조를 보여줍니다.
OpenCode, Antigravity, Codex, Claude Code, Gemini CLI, OpenClaw: 에이전트 툴이 쏟아지는 이유
2025~2026의 차이는 “AI 코딩 툴이 또 하나 늘었다”가 아닙니다. 에이전트 툴이 쏟아지는 가장 큰 이유는 단순한 유행이 아니라 효용성이 이미 너무 크기 때문입니다. 코드베이스 이해, 파일 수정, 실행, 검증, 재시도, 병렬 작업을 하나의 루프로 묶으면 개발자의 병목이 “직접 타이핑”에서 목표 설정, 검토, 승인, 아키텍처 판단으로 이동합니다.
6-1. 왜 이렇게 많이 등장하는가: 효용성이 이미 증명됐기 때문
에이전트 툴의 가치는 “코드를 조금 빨리 쓰는 것”보다 훨씬 큽니다. 사람이 하던 탐색, 수정, 실행, 실패 분석, 재시도, 문서화를 한 작업 루프로 묶기 때문에, 소프트웨어 작업의 대기 시간과 전환 비용을 크게 줄입니다.
시간 절감
개발자는 파일을 하나씩 찾고, 명령을 기억하고, 실패 로그를 붙여넣는 시간을 줄입니다. agent는 관련 파일 탐색, diff 작성, 테스트 실행, 에러 분석, 재수정을 한 번에 이어갑니다.
컨텍스트 흡수
새 코드베이스나 오래된 레거시 프로젝트에서도 agent가 구조를 읽고 관계를 요약합니다. 온보딩, 영향 범위 파악, 리팩터링 계획처럼 시간이 오래 걸리던 작업이 짧아집니다.
병렬 실행
사람 한 명은 보통 한 작업에 묶이지만, agent는 테스트 수정, 문서 갱신, 버그 재현, PR 준비 같은 독립 작업을 병렬로 돌릴 수 있습니다. 그래서 툴의 효용은 개인 생산성뿐 아니라 팀 처리량으로 이어집니다.
핵심: 이 시장이 커지는 이유는 모델 성능 경쟁만이 아니라, 실제 업무 시간을 줄이고, 기존 코드베이스를 다루는 비용을 낮추며, 여러 작업을 동시에 진행할 수 있게 만드는 경제적 효용이 너무 명확하기 때문입니다.
예전: point tool 시대
코드 자동완성, 특정 IDE 플러그인, 단일 diff 제안, 제한된 코드 검색처럼 한 지점의 편의성을 높이는 도구가 중심이었습니다. 툴마다 장점 하나와 불편 여러 개가 분리돼 있었습니다.
지금: agent runtime 시대
최신 툴은 코드베이스 읽기, 파일 수정, 명령 실행, 테스트, 재질문, PR 생성, 병렬 태스크, 로그·diff 검토를 하나의 실행 루프로 묶습니다. 즉 “답변기”가 아니라 “작업기”에 가깝습니다.
선택 기준도 달라짐
이제 중요한 것은 어느 모델이 더 똑똑한가만이 아닙니다. 터미널/IDE/브라우저/채팅앱/클라우드 샌드박스 중 어디에서 움직이는지, 병렬화·메모리·승인 게이트·로그를 어떻게 제공하는지가 실제 생산성을 가릅니다.
6-2. 주요 agentic coding / execution 툴 한눈에 보기
공식 문서만 보면 공통점이 분명합니다. 각 툴은 서로 다른 표면에서 동작하지만, 대부분 이미 계획 → 수정 → 실행 → 검증 → 병렬화의 기본 루프를 제공합니다.
툴
공식 포지셔닝
주요 실행 표면
공식 문서에 명시된 핵심 기능
현업에서 읽히는 의미
OpenCode
open-source AI coding agent
Terminal / IDE / Desktop
LSP enabled, multi-session, share links, any model, any editor
모델 락인 없이 여러 agent를 병렬로 돌리면서 같은 프로젝트를 다루기 좋은 구조
Codex
cloud-based software engineering agent
Cloud sandbox / Repo task board
many tasks in parallel, repo-preloaded sandbox, test/lint/typecheck, PR workflow
6-3. Application 시대의 종말, Application Layer를 넘어선 Agent Layer 시대
앞으로 사용자는 “어떤 앱을 열어야 하는가”보다 “무슨 일을 끝내고 싶은가”를 먼저 말하게 됩니다. 그러면 agent layer가 필요한 UI, 도구, 모델, 브라우저 작업, 파일 수정, 승인 흐름을 그때그때 조합해 실행하고, 일이 끝나면 그 표면은 바뀌거나 사라지는 방향으로 갑니다. OpenClaw는 이 변화를 보여주는 대표적인 runtime/manager 계층 사례입니다.
왜 Application Layer가 약해지는가
정적인 앱을 찾아 열고 기능을 탐색하는 방식보다, 목표를 말하고 agent가 workflow를 조합하는 방식이 더 빠릅니다.
앱은 고정된 목적물보다, 특정 과업을 처리하기 위해 잠시 생성되는 작업 표면(work surface)으로 바뀝니다.
사용자는 메뉴 탐색보다 목표·제약·권한·승인 기준을 지정하는 역할로 이동합니다.
같은 사용자도 과업마다 다른 app/agent 조합을 즉석에서 불러 쓰게 됩니다.
왜 Agent Layer가 위로 올라오는가
agent layer는 모델 선택, memory, routing, browser/shell/file tool, 권한 경계, background task를 하나의 실행 계층으로 묶습니다.
OpenClaw 같은 runtime은 채팅앱을 front-end로 두고, 뒤에서 여러 모델·도구·작업을 상주형으로 운영합니다.
핵심 가치는 “답변 품질”만이 아니라 관찰성, 재시도, replay, 승인 게이트, 정책 준수로 이동합니다.
결국 사용자는 개별 앱 사용자가 아니라 agent fleet operator에 가까운 역할을 맡게 됩니다.
앱 선택 → 목표 선언고정 UI → 과업별 생성 UI사용자 조작 → agent orchestration + human approval
Sam Altman은 The Gentle Singularity에서 “2025 has seen the arrival of agents that can do real cognitive work”라고 썼고, 같은 글에서 “A lot more people will be able to create software”라고 전망했습니다. 또 GPT-4o 글에서는 AI로 인해 사람들이 “create all sorts of amazing things”를 하게 되고, 컴퓨터로 “much more than ever before”를 하게 될 미래를 언급했습니다. 여기에 OpenAI가 2025년 10월 공개한 Apps in ChatGPT와 Apps SDK를 함께 보면, 소프트웨어는 미리 설치해 두는 고정 애플리케이션보다 필요할 때 생성·조합되어 과업을 수행하는 agentic surface에 가까워지는 방향으로 읽을 수 있습니다.
이 장은 OpenCode로 출발하여 agentic coding을 적용하고, 이후 harness engineering 관점에서 병렬 실행·감독형 운영으로 확장한 적용 사례를 화면으로 보여주는 파트입니다.
흐름: OpenCode 기반 단일 세션 보조 → 패치·재빌드·검증 폐루프 → 외부 스크립트 자동화 → 멀티 에이전트 병렬 실행 → 사람의 감독·승인 중심 운영.
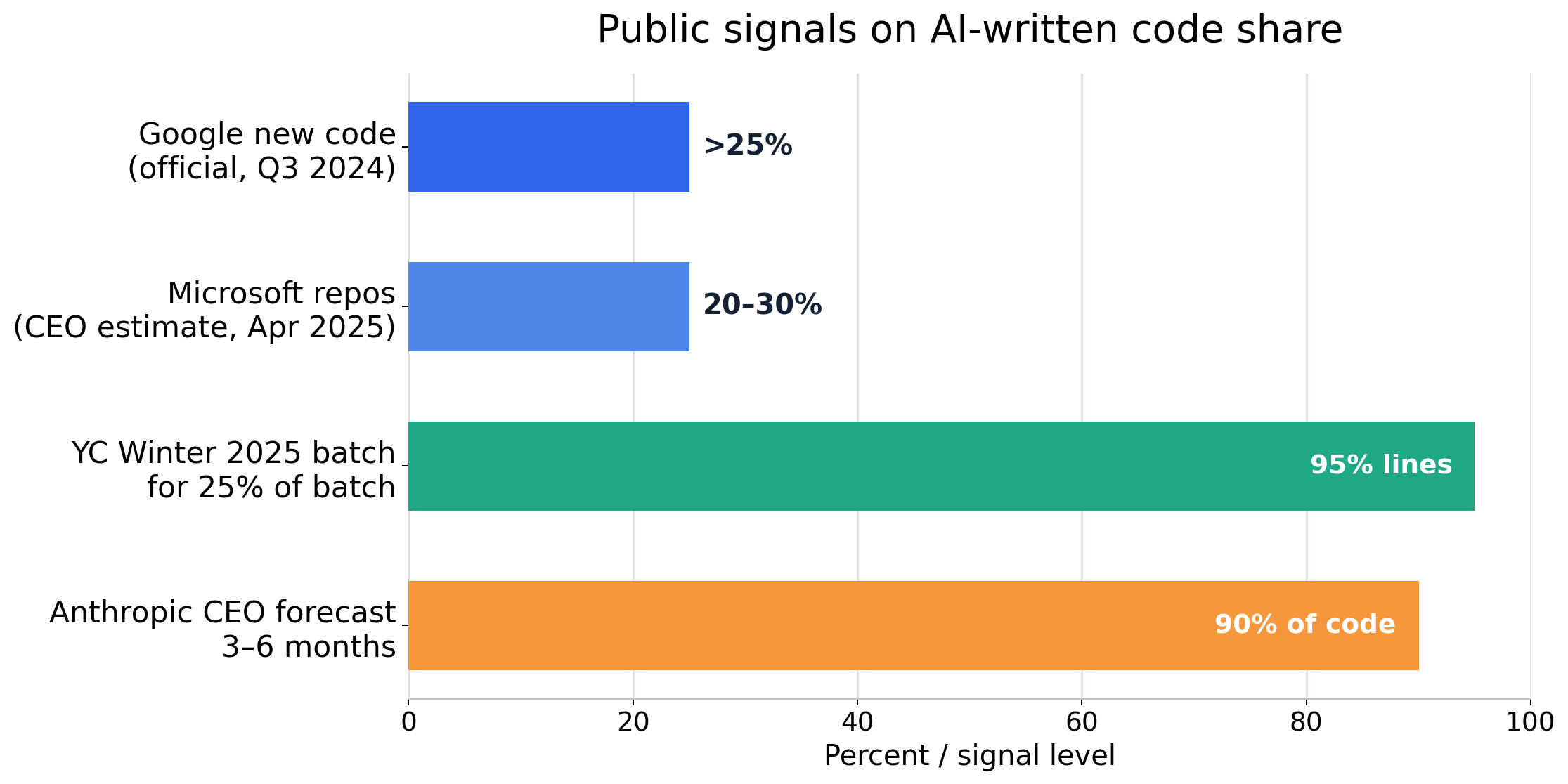
소프트웨어는 이미 가장 빠르게 AI화되는 영역
공개 수치와 업계 리더의 발언을 보면, 소프트웨어는 AI-generated code share가 가장 먼저 크게 올라간 분야입니다. 대기업 내부 측정치는 25~30% 수준까지 올라왔고, 스타트업 일부 cohort에서는 95% 사례가 보고됐으며, 업계 리더는 90%+ 구간을 전망하고 있습니다.
무엇을 고칠지, 무엇을 통과로 볼지 먼저 명시합니다. 이후 에이전트는 이 기준을 중심으로 작업을 분해합니다.
2
OpenCode로 초안 생성
파일을 읽히고 수정안·스크립트·문서를 생성합니다. 사람은 모든 코드를 직접 치기보다 작업 의도와 제약을 줍니다.
3
실행·검증·재질문 루프
빌드, 테스트, 로그, 에러 메시지, diff를 다시 읽혀서 원인을 추정하고 다음 수정안을 생성하는 폐루프를 만듭니다.
4
배치화·병렬화
동일한 패턴의 작업을 큐로 올리고 여러 워커를 동시에 돌립니다. 사람은 개별 작업보다 전체 큐의 throughput을 보게 됩니다.
5
감독(모니터링) 모델
최종적으로는 에이전트가 컴파일·검증·대안 제시를 수행하고, 사람은 선택·승인·예외만 감독하는 방식으로 전환합니다.
예시 1. 한 세션에서 원인 분석과 수정 방향 정리
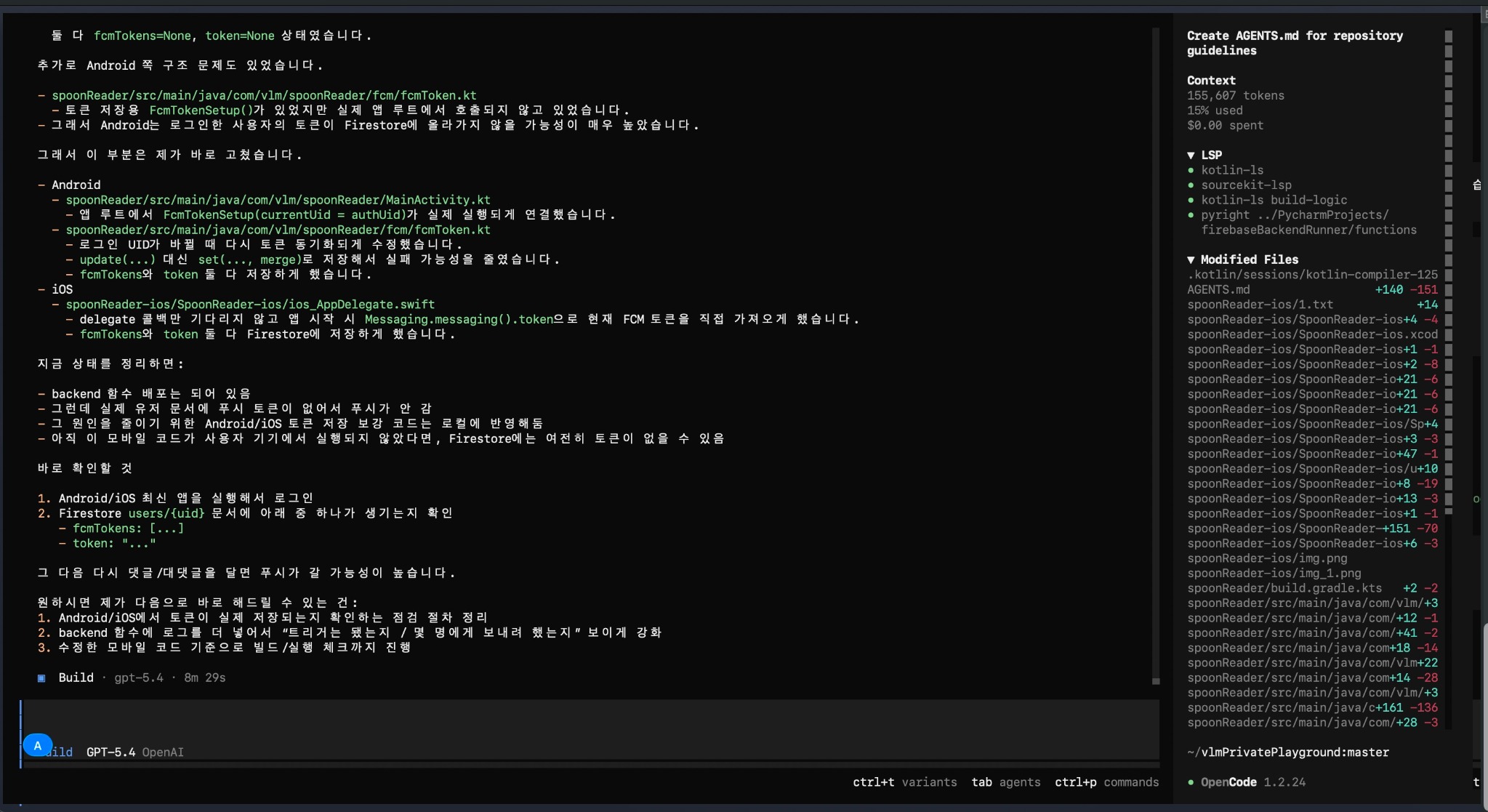
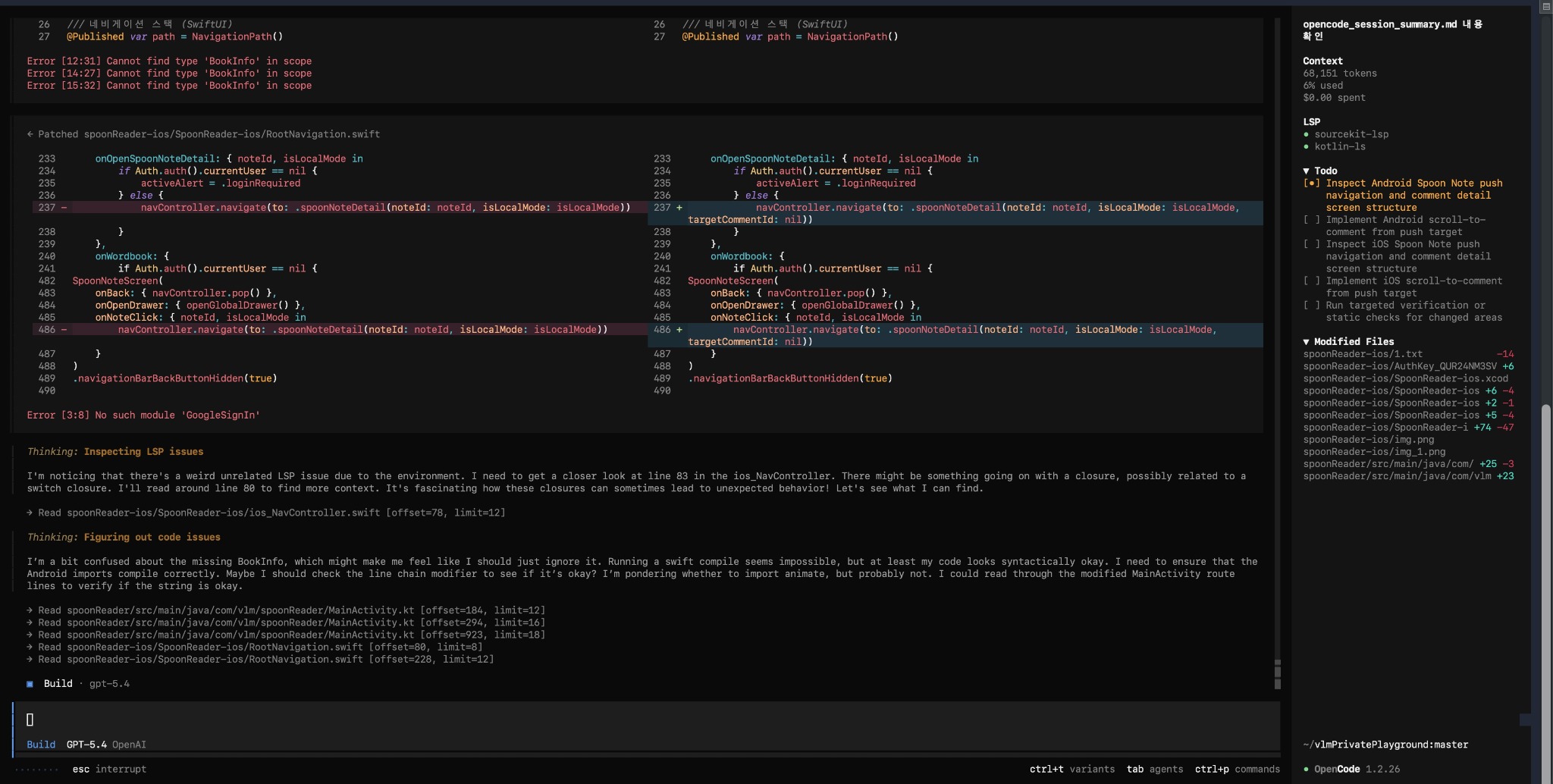
초기 단계에서는 OpenCode 단일 세션으로 문제 원인을 분석하고, 어떤 파일을 왜 바꿔야 하는지 설명받는 방식으로 사용했습니다. 이 단계만으로도 사람이 직접 코드를 모두 뒤지지 않고 빠르게 문제 구조를 파악할 수 있었습니다.
예시 2. diff와 오류 메시지를 다시 읽혀 다음 패치를 생성
다음 단계에서는 에러 메시지, 수정 diff, 다음에 읽을 파일 위치를 다시 모델에 넣어 폐루프를 만들었습니다. 즉, “답변”이 아니라 “패치 → 재빌드 → 재질문” 루프를 만들기 시작한 단계입니다.
예시 3. 외부 스크립트·도구까지 확장한 자동화
이후에는 단일 코드 수정에 그치지 않고, 배치 처리와 로그 생성, 진행 옵션 제어, 외부 스크립트까지 포함하는 자동화 파이프라인으로 확장했습니다. 즉 에이전트를 IDE 보조가 아니라 실제 작업 파이프라인의 일부로 붙인 것입니다.
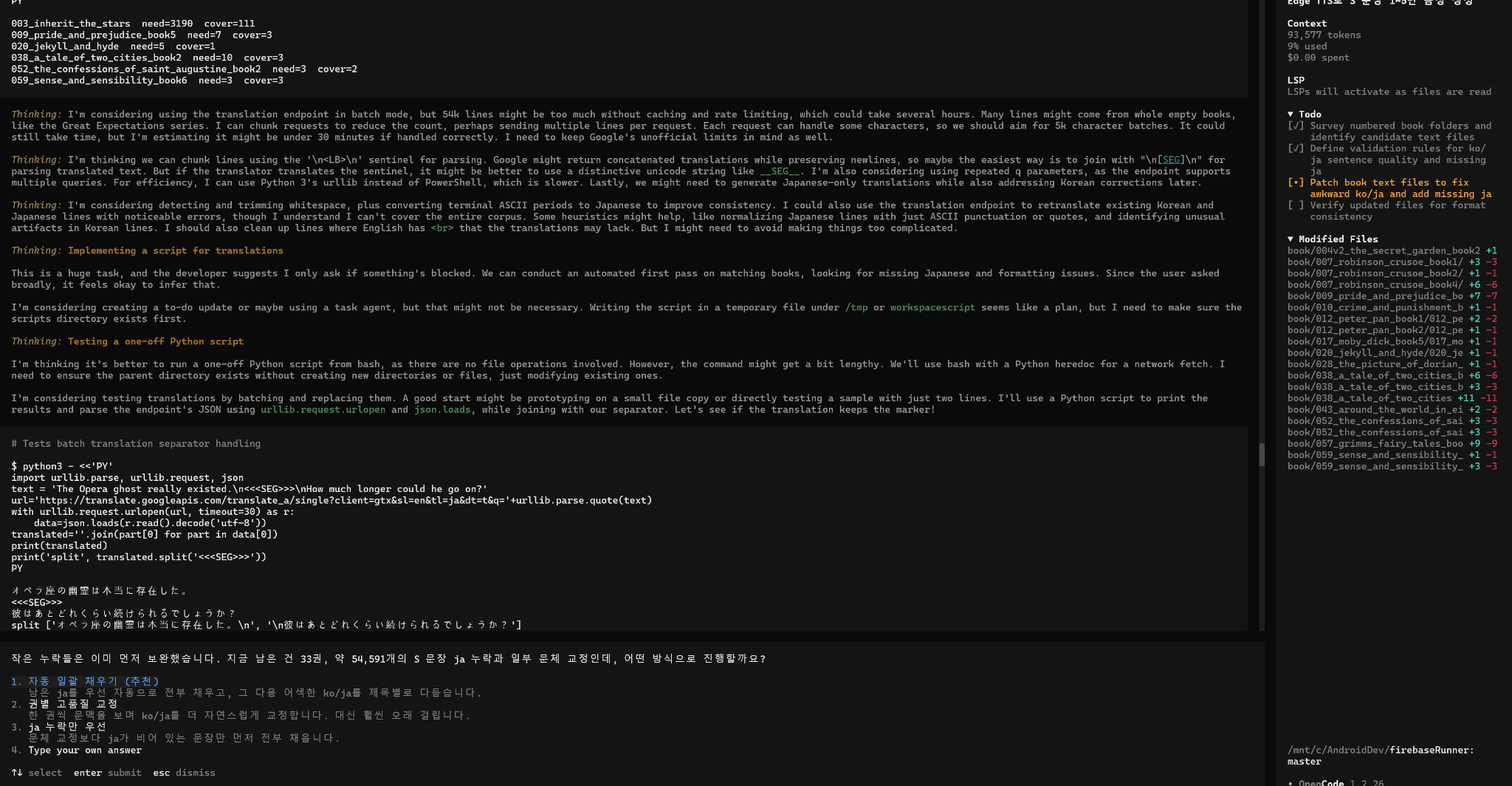
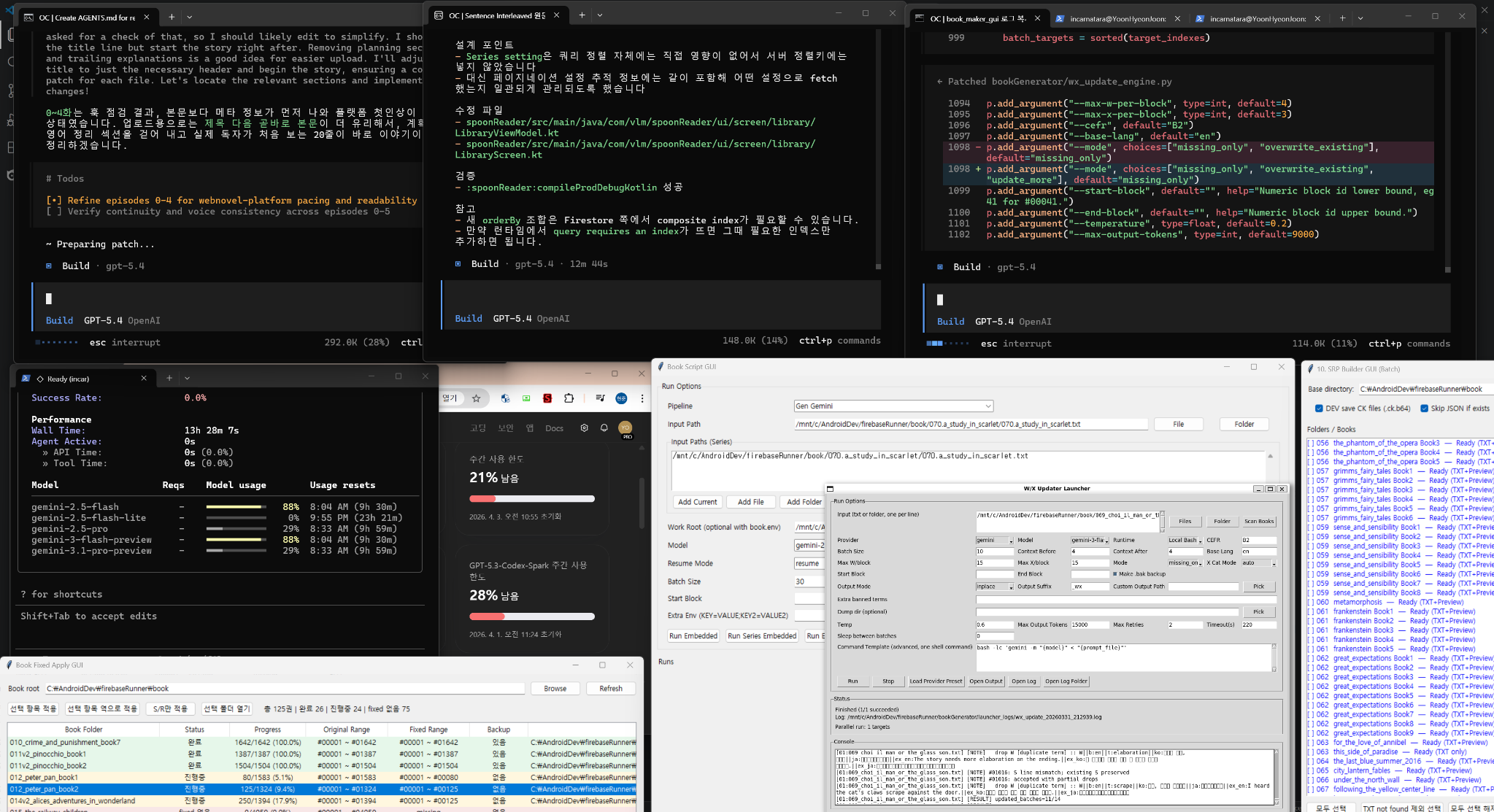
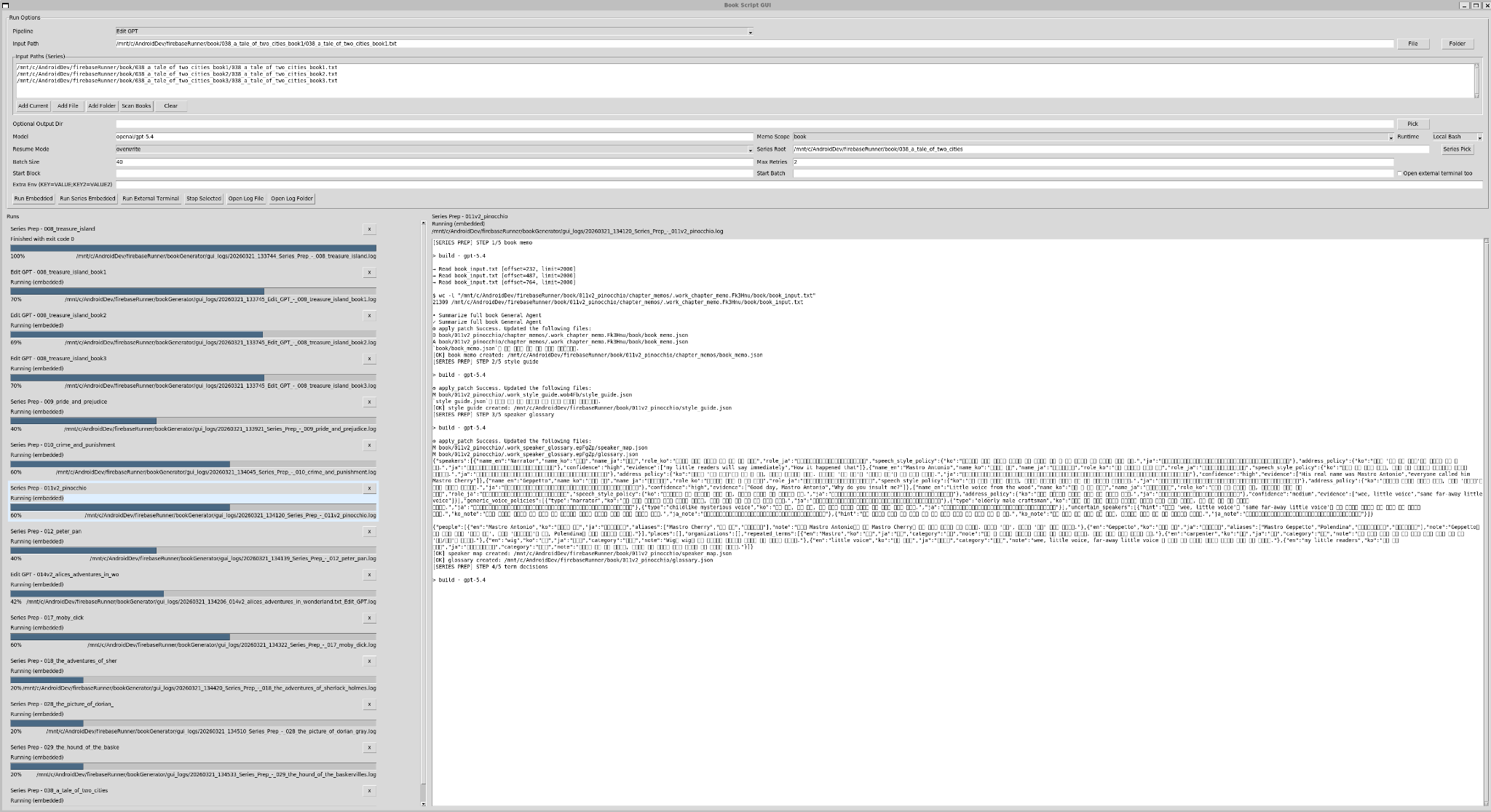
예시 4. 모든 프로세스를 한눈에 모니터링하며 에이전트 상호작용을 감독
이 화면은 여러 에이전트가 각자 코딩, 검증, 아이디어 제시를 수행하고 그 결과를 사용자가 한눈에 모니터링하는 상황을 보여줍니다. 즉 사람은 직접 한 작업을 치는 것이 아니라, 에이전트들이 상호작용하며 내놓는 산출물과 예외를 감독하는 역할로 이동합니다.
예시 5. 다수의 LLM을 병렬 호출하고 진행률·병합·로그를 관리
이 단계에서는 여러 모델과 런을 동시에 호출해 progress, 로그, 병합 결과를 관리합니다. 결국 사람은 전체 실행 팜의 상태를 보면서 실패 작업만 집어 들고, 성공한 작업은 계속 자동으로 흘려 보내는 운영 모델에 가까워집니다.
이 파이프라인을 하드웨어로 옮기면
핵심은 도메인이 아니라 운영 구조입니다. 목표 정의, 초안 생성, 실행/검증, 재질문, 재시도, 병렬 운영, 승인 게이트라는 구조는 앱 개발에서 통했던 것과 같은 방식으로 메모리·낸드 설계/검증/제품화 workflow에도 그대로 이식할 수 있습니다.
루프 단계
실제 적용 사례에서 한 일
메모리·낸드 설계/검증/제품화로 확장했을 때
목표 정의
수정 목표, 통과 기준, 파일 범위, 산출물 형식을 먼저 명시
Spec, 인터페이스 제약, timing 목표, 검증 통과 기준, sign-off 조건을 명시
초안 생성
코드 수정안, 스크립트, 문서 초안, 패치 후보 생성
RTL 초안, UVM sequence/scoreboard 골격, TCL/pytest/regression 스크립트, 체크리스트 초안 생성
실행/검증
빌드, 실행, 번역/패치, 결과 로그 수집
lint, compile, simulation, regression, waveform/log 수집, coverage/리포트 자동 생성
재질문/재시도
오류와 diff를 다시 읽혀 다음 수정안을 자동 생성
실패 testcase 분류, 에러 signature 추출, 의심 RTL/UVM 구간 재분석, 수정안 제안 후 재실행
병렬 운영
여러 작업을 동시에 올리고 큐 단위로 처리
corner별 회귀, block별 verification, firmware/driver/validation 병렬 실행, issue triage 큐 운영
감독과 승인
실패 작업, 재시도, 예외 로그, 승인 여부만 사람이 관리
설계자는 승인 게이트, 우선순위, 품질 기준, tape-out / 제품화 리스크를 관리
앱 개발에서 검증된 운영 구조설계/검증/제품화로 동일한 루프 이식 가능사람의 역할은 승인·우선순위·책임 관리로 이동
10 OPENCODE TIPS
OpenCode 사용 팁
OpenCode에서는 다섯 가지를 구분해 보면 덜 헷갈립니다. AGENTS.md는 기본 행동 규칙, command는 사용자가 직접 치는 슬래시 명령, skill은 에이전트가 필요할 때만 불러오는 작업 플레이북, MCP는 외부 도구·데이터 연결 표준, /init은 저장소를 스캔해 AGENTS.md를 만들거나 다듬는 내장 명령입니다.
AGENTS.md = 기본 행동 규칙
프로젝트 루트의 AGENTS.md는 그 디렉터리 이하에서 적용되고, ~/.config/opencode/AGENTS.md는 모든 세션에 공통 적용됩니다. OpenCode는 시작 시 현재 디렉터리에서 위로 올라가며 로컬 규칙을 찾고, 그다음 글로벌 규칙, 마지막으로 Claude Code 호환용 CLAUDE.md를 fallback으로 봅니다.
예시처럼 AGENTS.md에는 저장소 범위, 실제 엔트리포인트, 자주 쓰는 명령, 검증 방법, 건드리면 안 되는 파일 같은 프로젝트 기본 운영 규칙을 모아 둡니다. 그래서 새 세션을 열어도 에이전트가 같은 작업 기준을 공유합니다.
빌드·린트·테스트 명령, 중요한 실행 순서, 저장소 구조, 프로젝트 특유의 컨벤션과 운영상의 주의점을 적어 두는 곳입니다.
command = 사용자가 직접 실행하는 매크로
/test, /review 같은 커스텀 슬래시 명령입니다. opencode.json의 command 항목으로 정의하거나, .opencode/commands/ 또는 ~/.config/opencode/commands/ 아래 markdown 파일로 만들 수 있습니다.
TUI에서 /help, /review, /skills처럼 사용자가 직접 선택해 실행하는 계층입니다. 즉 command는 에이전트가 알아서 불러오는 지식 모듈이 아니라, 사람이 반복 작업을 매크로처럼 호출하는 슬래시 명령입니다.
내용은 프롬프트 템플릿이고, $ARGUMENTS, $1, $2 같은 인자 치환, !명령어의 셸 출력 주입, @파일경로의 파일 자동 포함도 지원합니다. 특정 agent·model 지정과 subtask 강제도 가능합니다.
skill = 에이전트가 필요할 때만 여는 작업 플레이북
스킬은 SKILL.md 기반의 재사용 가능한 지침입니다. OpenCode는 먼저 스킬 목록과 설명만 보고, 에이전트가 필요하다고 판단할 때 native skill tool로 본문을 로드합니다. 즉 기본 프롬프트에 항상 다 들어가는 것이 아니라 온디맨드로 불러오는 지식 모듈입니다.
예시처럼 skill은 Firebase, Genkit, Firestore, 배포 같은 작업별 폴더로 나뉘고 각 폴더의 SKILL.md가 전문 플레이북 역할을 합니다. AGENTS.md가 항상 깔리는 기본 규칙이라면, skill은 필요한 순간에만 열어 보는 작업별 매뉴얼입니다.
경로는 .opencode/skills/<name>/SKILL.md 또는 ~/.config/opencode/skills/<name>/SKILL.md를 쓰고, YAML frontmatter의 name과 description이 필수입니다.
MCP = 외부 도구·데이터 연결 표준
MCP는 OpenCode 고유 포맷이 아니라 Model Context Protocol이라는 외부 표준입니다. 공식 문서는 이를 AI용 USB-C 포트에 비유합니다. OpenCode에서는 opencode.json의 mcp 항목에 서버를 등록해 로컬·리모트 MCP를 붙입니다.
핵심은 저장소 안 규칙을 정리하는 것이 아니라 GitHub·Jira·문서 검색기 같은 바깥 시스템과 연결해 실제 도구와 데이터를 가져오게 하는 것입니다. MCP는 컨텍스트 사용량을 크게 늘릴 수 있으므로 많이 붙일수록 무거워질 수 있습니다.
더보기
정확히 말하면 MCP 서버가 LLM과 직접 대화하는 것은 아닙니다. OpenCode, Claude Desktop, Cursor 같은 AI 앱이 MCP Host이자 MCP Client가 되고, 외부 기능을 제공하는 프로그램이 MCP Server가 됩니다. LLM은 Host가 알려준 tool schema를 보고 “어떤 도구를 쓸지” 결정하고, 실제 통신과 실행은 Host와 MCP Server가 JSON-RPC로 처리합니다.
1. 사용자 요청2. OpenCode 같은 AI Host가 LLM에 tool 목록과 schema 제공3. LLM이 필요한 tool 호출을 결정4. Host 내부 MCP Client가 MCP Server에 JSON-RPC 요청 전송5. MCP Server가 실제 파일/API/DB/명령을 실행6. 결과를 JSON-RPC 응답으로 반환7. Host가 결과를 LLM context에 넣고, LLM이 최종 답변 생성
구성
역할
예시
Resource
읽기용 데이터
파일 내용, DB schema, 문서, 설정값
Tool
실행 가능한 함수
검색, 빌드 실행, 테스트 실행, API 호출
Prompt
재사용 프롬프트 템플릿
코드 리뷰 템플릿, SVA 리뷰 템플릿
JSON-RPC로 보면: Host는 먼저 initialize로 protocol version과 capability를 맞추고, tools/list로 tool 목록을 가져오며, 실제 실행은 tools/call 요청으로 합니다.
로컬 stdio 방식: OpenCode가 MCP 서버를 subprocess로 실행하고, stdin/stdout으로 JSON-RPC 메시지를 주고받습니다. 그래서 MCP 서버에서 debug용 print()를 stdout에 막 쓰면 통신이 깨질 수 있고, 로그는 stderr로 보내는 것이 안전합니다.
RTL/DV에 붙이면:search_signal, read_rtl_file, find_module, parse_sim_log, extract_assertion_failures, generate_sva_candidate 같은 tool을 만들 수 있습니다. 그러면 자연어 요청 하나가 내부적으로 파일 검색 → RTL 읽기 → 로그 분석 → SVA 후보 생성 같은 tool 호출 체인으로 바뀝니다.
보안 포인트: MCP tool은 실제 파일 읽기, command 실행, API 호출, DB 접근을 할 수 있으므로 위험할 수 있습니다. 임의 shell command를 그대로 받는 tool보다 unit_test, lint, sim_smoke처럼 허용된 작업만 enum으로 제공하는 방식이 안전합니다.
한 줄 요약: MCP는 “AI가 외부 기능을 호출할 수 있도록 함수 목록, 입력 스키마, 실행 결과를 JSON-RPC로 표준화한 client-server 프로토콜”입니다.
아래 흐름은 “하네스 엔지니어링을 하드웨어 RTL 설계/검증 모델로 시각화해 달라”는 요청을 Stitch에 만들고, OpenCode가 MCP 서버를 통해 그 화면과 산출물을 읽고 개선하는 예시입니다. 발표에서는 1번부터 9번까지 순서대로 보면 MCP가 단순 설정 파일이 아니라 외부 도구를 에이전트 작업 루프에 붙이는 연결 표준이라는 점이 드러납니다.
1
기준 UVM 테스트벤치 이미지 준비
기존 UVM Testbench 구조를 기준 이미지로 준비합니다. 이후 Stitch와 에이전트는 이 이미지를 출발점으로 하네스 엔지니어링 구조를 확장합니다.
2
Stitch에 목표 입력
첨부한 기준 이미지를 하드웨어 개발·검증용 하네스 엔지니어링 모델로 확장해 달라고 Stitch에 요청합니다.
3
Stitch 화면과 MCP 연결 준비
Stitch가 만든 UVM testbench 참조와 아키텍처 다이어그램을 확인하고, 오른쪽 패널에서 OpenCode MCP 연결을 준비합니다.
4
OpenCode에 MCP 서버 등록
opencode.json의 mcp 항목에 Stitch 서버를 등록합니다. 로컬 작업기인 OpenCode가 외부 디자인 도구를 호출할 수 있는 통로가 생깁니다.
5
TUI에서 연결 상태 확인
OpenCode TUI의 MCP 상태 창에서 stitch connected와 Enabled 상태를 확인합니다. 이때부터 에이전트가 Stitch 도구를 쓸 수 있습니다.
6
에이전트가 Stitch 화면을 읽음
에이전트가 stitch_get_screen, stitch_list_screens 같은 MCP 도구로 화면과 산출물을 읽고, HTML 다이어그램으로 옮길 구조를 추출합니다.
/init은 TUI의 built-in command이며, 역할은 저장소를 스캔해 AGENTS.md를 새로 만들거나 기존 파일을 개선하는 것입니다. 코드만으로 알 수 없는 부분은 몇 가지 질문을 던지고, 이후 세션에 필요한 build/lint/test 명령, 아키텍처, 관례, 주의사항을 요약해 넣습니다.
흐름으로 보면 /init이 먼저 기본 규칙을 깔고, 평소 세션에서는 AGENTS.md가 기본 행동을 잡아주며, 사용자는 /command로 반복 작업을 직접 실행하고, 에이전트는 필요할 때 skill을 불러 작업 방식을 보강하고, 외부 접근이 필요할 때 MCP를 통해 바깥 도구와 데이터를 씁니다.
추천 팁 1 · permission 설계를 먼저 해두기
OpenCode는 어떤 행동을 자동 실행할지, 물어보고 실행할지, 막을지를 permission으로 제어합니다. 문서상 legacy tools 설정은 deprecated 되었고 permission 체계로 합쳐졌기 때문에, 실제 운영에서는 기능 추가보다 권한 설계가 먼저라는 관점이 중요합니다.
bash, 파일 수정, MCP 계열을 allow / ask / deny로 나누는 감각이 중요합니다. 에이전트 도입의 핵심은 기능 추가보다 권한 설계에 가깝습니다.
추천 팁 2 · build와 plan을 분리해 쓰기
OpenCode 공식 문서는 build를 기본 개발용 agent, plan을 코드 변경 없이 분석·계획만 하는 제한형 agent로 설명합니다. 그래서 처음부터 다 맡기기보다, 먼저 plan으로 분석하고 그다음 build로 실행하는 2단계 운영이 실무적으로 안정적입니다.
세션 중에는 Tab으로 primary agent를 전환할 수 있고, subagent는 @mention으로 직접 호출할 수 있습니다. 즉 “생각은 plan, 실행은 build”로 역할을 나누는 방식이 추천됩니다.
헷갈리기 쉬운 포인트:AGENTS.md는 규칙 파일이고, 문서의 Agents는 설정 가능한 AI assistant 객체입니다. 실제 agent 정의는 opencode.json의 agent 항목이나 .opencode/agents/ markdown 파일로 구성합니다. 이름은 비슷하지만 다른 레이어입니다.
이 파트는 보안 사고의 시시비비보다, 유출 이후 커뮤니티가 무엇을 빠르게 읽어냈는가에 집중합니다. 핵심은 weights가 아니라 agent product layer가 공개됐고, 그 결과 구조 분석 · 기능 해석 · 재구현 · 로드맵 추정이 거의 실시간으로 일어났다는 점입니다.
유출로 드러난 사실
노출된 것은 주로 Claude Code의 TypeScript 제품 코드였고, 초점은 모델 자체보다 CLI · orchestration · tool wiring · feature flags · 운영 로직에 있었습니다.
즉 경쟁력의 상당 부분이 이제 weights만이 아니라 agent harness와 product layer에 있다는 사실이 더 선명해졌습니다.
커뮤니티는 대규모 코드베이스를 빠르게 읽어내며 memory 구조, 세션 운영 방식, 장시간 실행형 workflow, 내부 기능 스위치 같은 레이어를 해석하기 시작했습니다.
왜 이 사건이 역설적으로 중요했는가
50만 줄대 제품 레이어가 공개되자, 커뮤니티와 AI가 요약 · 리포맷 · 재구성 · 부분 재구현을 매우 빠르게 진행했습니다.
이것은 현대 LLM이 단순 답변기를 넘어, 거대한 코드베이스를 분석하고 다른 형태로 옮기는 데 매우 강력하다는 점을 역설적으로 보여줍니다.
다시 말해 앞으로는 모델 가중치가 아니더라도, agent runtime과 harness 설계만 공개돼도 제품 철학과 향후 방향성이 상당 부분 읽히는 시대가 됐습니다.
사람들이 읽어낸 가능성
상시 실행형 background agent에 가까운 운영 방식이 더 중요해질 수 있다는 점입니다. 세션은 답변 한 번으로 끝나는 것이 아니라, 오래 살아 있으면서 상태를 이어받는 쪽으로 갑니다.
멀티 에이전트 협업도 더 강화될 가능성이 큽니다. 단일 세션보다 여러 에이전트가 역할을 나누고, 서로 메시지를 주고받으며, 작업을 병렬로 진행하는 방향이 더 뚜렷해졌습니다.
툴 실행 → 상태 모니터링 → 결과 수집 → 후속 작업 재개의 폐루프도 더 정교해질 가능성이 큽니다. 즉 에이전트는 호출형이 아니라 운영형 시스템으로 이동합니다.
현재 공식 문서와 연결해서 보면
공식 문서에는 이미 Agent Teams, Remote Control, Channels, scheduled tasks, PR status monitoring 같은 흐름이 드러나 있습니다.
Channels는 Telegram · Discord · iMessage · webhooks · monitoring events를 세션에 밀어 넣는 구조를 설명하고, Agent Teams는 에이전트 간 직접 메시징과 공유 task list를 설명합니다.
따라서 앞으로는 메신저로 세션을 제어하고, 멀티 에이전트 간 커뮤니케이션을 강화하며, 외부 이벤트와 모니터링 결과를 받아 다음 작업을 이어가는 운영형 에이전트가 더 강화되는 방향으로 읽는 것이 자연스럽습니다.
한 줄 요약: Claude Code 유출은 단순 유출 사건을 넘어, 사람과 LLM이 agent product layer를 거의 실시간으로 해석·재구성하고 미래 기능까지 추론하는 시대가 왔음을 보여준 사례였습니다.
Harness engineering은 에이전틱 코딩을 잘 하도록 “파이프라인 하나를 짜는 일”보다 더 넓습니다. 더 정확히는 모델이 실제로 일을 끝내도록 state · prompts · tools · permissions · memory · verification · observability · retry loop · artifact handoff를 설계하는 시스템 설계·운영 practice입니다.
핵심 개념
Model = intelligenceHarness = state + tools + constraints + feedback loops파이프라인 설계는 일부, 운영 설계가 본체
항목
쉽게 말하면
State / Memory
긴 작업이 끊겨도 이어서 할 수 있게 남기는 파일, 계획, 메모, 세션 간 artifact
Tools
쉘, 테스트 러너, 브라우저, git, 코드 실행 환경, 외부 MCP 연결
Constraints / Permissions
해도 되는 것과 안 되는 것, 아키텍처 경계, 보안·품질 규칙, 승인 정책
Verification
빌드, 테스트, 로그, 영상 캡처, 비교 실행으로 스스로 확인하는 루프
Observability
사람이 진행 상황과 실패 원인을 한눈에 볼 수 있는 로그, 대시보드, 결과 파일
OpenAI가 보여준 것
OpenAI는 Codex로 0줄 수동 코드 제약 아래 내부 베타 제품을 만들었고, 약 100만 줄 코드, 약 1,500개 PR, 약 1/10 시간 수준의 생산성 향상을 소개했습니다.
핵심은 모델이 아니라 환경이었습니다. 짧은 AGENTS.md를 목차처럼 두고, 상세 지식은 저장소 문서 체계 안에 두며, custom lint와 구조 규칙으로 agent가 빠르게 움직여도 아키텍처가 무너지지 않게 만들었습니다.
결국 사람의 역할은 코드를 직접 쓰는 것보다 환경·피드백 루프·제어 시스템을 설계하는 쪽으로 이동했습니다.
Anthropic이 보여준 것
Anthropic은 장시간 작업의 핵심 문제를 여러 context window를 넘나들 때 진행이 끊기는 것으로 설명했습니다.
해결 방식은 initializer agent가 환경을 세팅하고, coding agent가 각 세션마다 다음 세션을 위한 명확한 artifact를 남기도록 하는 구조였습니다.
또 다른 글에서는 generator–evaluator 같은 멀티 에이전트 구조가 frontier agentic coding 성능을 더 끌어올릴 수 있다고 설명했습니다.
정의를 더 정확히 말하면
“에이전틱 코딩을 잘 하도록 파이프라인을 설계하는 방법론”이라는 표현도 크게 틀리지는 않지만, 더 정확히는 모델이 실제로 일을 끝내게 만드는 상태·도구·검증·관찰성·제약·아티팩트 흐름 전체를 설계하는 시스템 설계·운영 방식이라고 보는 편이 맞습니다.
왜 지금 중요해졌는가
agent가 한 번에 끝나는 답변형에서 장시간 실행형으로 넘어갔기 때문입니다.
문제는 추론 자체보다 상태 유지 · 재시도 · 도구 사용 · 실패 복구 · 사람 승인에서 더 자주 생깁니다.
따라서 앞으로의 경쟁력은 prompt 문장 하나보다 harness 설계 능력에서 갈릴 가능성이 큽니다.
여담 3. 4월 26일 업데이트: 모델 성능 경쟁보다 비용·메모리·운영 리스크가 더 중요해진다
이번 업데이트의 결론은 단순히 “GPT-5.5가 더 좋아졌다”가 아닙니다. 프론티어 모델 성능은 계속 오르고, GLM-5.1 같은 오픈 모델도 빠르게 추격하지만, 동시에 API 비용·구독 한도·DRAM/NAND 공급·로컬 장비 수요가 모두 압박 요인으로 바뀌고 있습니다.
1) GPT-5.5: 에이전트형 업무의 새 기준
OpenAI 공식 발표와 AI타임스 보도 기준으로 GPT-5.5는 2026년 4월 23일 ChatGPT와 Codex 유료 사용자에게 배포됐고, API는 안전·보안 요건을 거쳐 곧 제공될 예정입니다.
핵심 benchmark: Terminal-Bench 2.0 82.7%, SWE-Bench Pro 58.6%, Expert-SWE 73.1%, GDPval 84.9%, OSWorld-Verified 78.7%.
2) GLM-5.1: 오픈 모델이 실전 코딩을 위협
GLM-5.1은 Z.AI 문서상 2026년 4월 7일 릴리스로 표시되며, 관련 자료는 3월 27일 초기 접근 이후 4월 benchmark 업데이트를 함께 설명합니다. 첨부 벤치마크 기준 SWE-Bench Pro 58.4로 GPT-5.4와 Claude Opus 4.6을 근소하게 앞섭니다.
다만 HLE no-tools, GPQA, 일부 terminal/browser 지표에서는 여전히 Gemini/GPT/Claude 상위 모델이 앞서는 영역이 있습니다.
3) 로컬 LLM 수요: 메모리 시장까지 연결
고메모리 Mac mini와 Mac Studio 품절/장기 배송 보도는 로컬 에이전트 실행 수요가 실제 하드웨어 수급에 반영되는 신호입니다. AI 데이터센터 수요는 DRAM/NAND 가격과 납기에도 압력을 줍니다.
하드웨어 관점에서는 local/cloud 선택보다 routing, 캐시, 장시간 실행, 로그/검증, 내부 승인 체계를 함께 설계해야 합니다.
GPT-5.5 비용 리뷰: 성능은 올랐지만 단가도 2배
OpenAI 공식 API 가격표 기준 GPT-5.5는 GPT-5.4보다 입력·캐시 입력·출력 단가가 모두 정확히 2배입니다. 모델이 더 토큰 효율적일 수는 있지만, 장시간 agentic workflow에서는 호출 횟수와 tool loop가 늘어 총비용이 빠르게 커질 수 있습니다.
모델
입력 / 100만 토큰
캐시 입력 / 100만 토큰
출력 / 100만 토큰
해석
GPT-5.4
US$2.50
US$0.25
US$15.00
2026년 3월 기준 프론티어 업무 모델의 기준선.
GPT-5.5
US$5.00
US$0.50
US$30.00
GPT-5.4 대비 2배. 에이전트 코딩·전문 업무 성능 향상과 함께 가격도 상승.
GPT-5.5 Pro 예정
US$30.00
-
US$180.00
가장 어려운 연구·전문 업무용. 일반 자동화 파이프라인의 기본값으로 쓰기에는 비용 관리가 핵심.
무제한 요금제는 점점 압박받는다
OpenAI의 ChatGPT 책임자는 빠르게 발전하는 기술에서 가격 구조가 그대로 유지될 수 없다는 취지로 설명했고, 보도들은 “unlimited” 플랜이 사용량 기반·단계형 한도로 이동할 가능성을 다뤘습니다.
Anthropic 공식 도움말도 Claude 사용량은 모든 표면에서 같은 사용 한도에 집계되며, Pro/Max/Team에도 사용량 한도가 있다고 설명합니다.
TechCrunch는 Claude Code heavy user들이 200달러 Max 플랜에서도 갑작스러운 제한을 경험했다고 보도했습니다. 이는 fixed subscription이 고강도 agentic coding 사용을 영구히 감당하기 어렵다는 신호입니다.
2026년 4월 27일 기준 GitHub Trending Today 페이지에서 보이는 상위 10개 실제 레포를 간단히 정리했습니다. 눈에 띄는 점은 skills, code intelligence, agent memory, Claude/Codex workflow, multi-agent framework처럼 에이전트 실행 환경을 보강하는 레포들이 상단에 많이 올라왔다는 점입니다.